Understanding Machine Learning Supervised Learning Algorithms
In the vast realm of machine learning supervised learning Algorithms stands out as a powerful and widely used approach. This article aims to delve into the intricacies of supervised learning algorithms, exploring their principles, applications, and variations. Whether you’re a beginner or a seasoned data scientist, understanding the fundamentals of supervised learning is essential for harnessing the true potential of machine learning.
I. The Foundation of Supervised Learning
Definition and Core Concepts
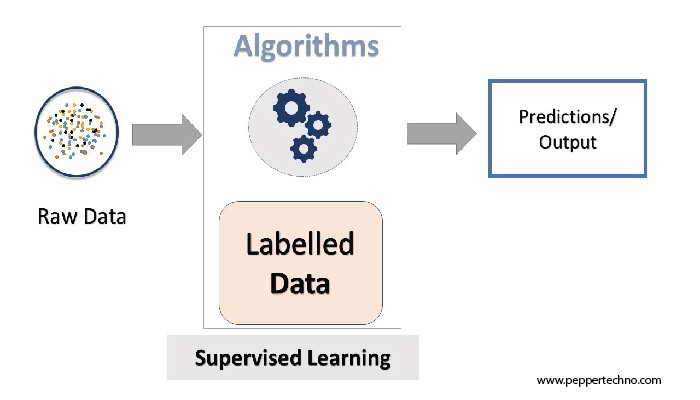
Supervised learning is a type of machine learning where the algorithm is trained on a labeled dataset, meaning it learns from examples that are explicitly labeled with the correct outcomes. The key elements of supervised learning include input features, output labels, training data, and a model that maps inputs to outputs. This paradigm enables the algorithm to make predictions or classifications on unseen data based on the patterns learned during training.
Importance of Labeled Data
Labeled datasets empower algorithms to recognize patterns and relationships between input features and corresponding outputs. The quality and quantity of labeled data directly impact the performance and generalization capabilities of supervised learning models.
II. Common Supervised Learning Algorithms
Linear Regression
It establishes a linear relationship between input features and the output, making it ideal for tasks such as predicting house prices, stock values, or any other numeric value.
Logistic Regression
Despite its name, logistic regression is employed for binary classification problems. It models the probability of an instance belonging to a particular class, making it a valuable tool for tasks like spam detection, medical diagnosis, and sentiment analysis.
Decision Trees
Decision trees are versatile and intuitive algorithms that partition the feature space into regions, making decisions based on the input features. Widely used for classification and regression tasks, decision trees are the building blocks for more complex ensemble methods like Random Forests.
Support Vector Machines (SVM)
SVMs are powerful algorithms used for both classification and regression. They work by finding the hyper plane that maximally separates different classes in the feature space. SVMs are effective in tasks with complex decision boundaries and are particularly useful in image recognition and text classification.
Neural Networks
Neural networks, inspired by the human brain, consist of interconnected nodes organized in layers. Deep neural networks, often referred to as deep learning models, have revolutionized various domains, including image recognition, natural language processing, and speech recognition. They excel in capturing intricate patterns from large and complex datasets.
III. The Supervised Learning Workflow
Data Preprocessing
Before training a supervised learning model, it’s crucial to preprocess the data. This step involves handling missing values, normalizing features, and encoding categorical variables. Clean and well-preprocessed data contribute to the model’s robustness and performance.
Model Training
The training phase involves feeding the algorithm with labeled data to learn the underlying patterns. During this process, the model adjusts its parameters to minimize the difference between predicted and actual outcomes. The choice of algorithm and its hyper parameters significantly influences the training process.
Model Evaluation
After training, it’s essential to assess the model’s performance on unseen data. Common evaluation metrics include accuracy, precision, recall, and F1 score for classification tasks, and mean squared error for regression tasks. Cross-validation techniques help ensure the model’s generalizability.
IV. Challenges and Considerations
Over fitting and under fitting
Balancing the complexity of a model is crucial to prevent over fitting (capturing noise in the training data) or under fitting (failing to capture the underlying patterns). Regularization techniques and proper tuning of hyper parameters mitigate these challenges.
Bias and Fairness
Supervised learning models may inherit biases present in the training data, leading to unfair predictions. Ensuring fairness and mitigating biases is an ongoing challenge, emphasizing the importance of ethical considerations in machine learning development.
V. Real-world Applications
Healthcare
Supervised learning plays a pivotal role in healthcare for tasks such as disease diagnosis, prognosis prediction, and personalized treatment recommendations. Medical imaging, genomic data analysis, and electronic health records benefit from the predictive capabilities of supervised learning models.
Finance
In the financial sector, supervised learning aids in credit scoring, fraud detection, and stock price forecasting. Algorithms can analyze historical data to identify patterns and make informed predictions, contributing to better risk management and investment decisions.
Natural Language Processing (NLP)
Natural Language Processing NLP applications, including sentiment analysis, machine translation, and chatbots, heavily rely on supervised learning. By learning from labeled text data, models can understand and generate human-like language, enhancing communication between machines and users.
Conclusion
Supervised learning algorithms form the bedrock of machine learning applications across diverse domains. From linear regression to deep neural networks, these algorithms enable machines to learn and make predictions based on labeled data. Understanding their principles, challenges, and real-world applications is essential for anyone venturing into the exciting field of machine learning. As technology continues to advance, supervised learning will undoubtedly remain a cornerstone, driving innovation and transforming industries.