Exploring the Depths of Machine Learning: Supervised and Unsupervised Learning Examples
In the ever-evolving landscape of artificial intelligence, machine learning plays a pivotal role in empowering systems to learn and make intelligent decisions. Two prominent paradigms within machine learning are supervised and unsupervised learning, each with its unique set of applications and examples. This article delves into the intricacies of these two learning approaches, shedding light on real-world instances where they prove their mettle.
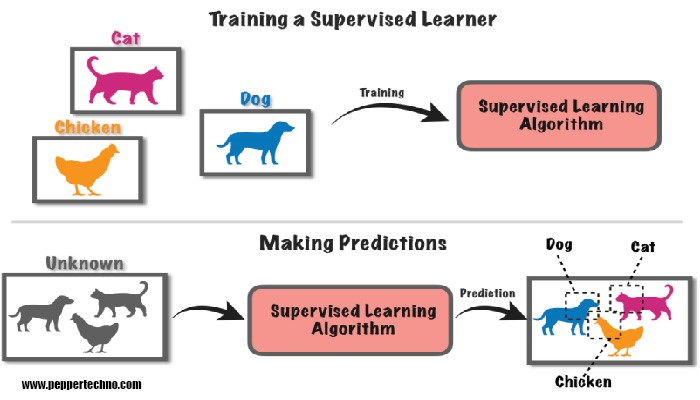
I. Understanding Supervised Learning
The goal is for the model to learn the mapping between inputs and outputs, enabling it to make accurate predictions or classifications when presented with new, unseen data.
Classification Tasks
One of the most common examples of supervised learning is classification. In this scenario, the algorithm learns to assign input data to predefined categories. A classic illustration is the use of email filters to distinguish between spam and legitimate emails. The algorithm learns from a labeled dataset, identifying patterns in the features of emails to predict whether a new email belongs to the spam or non-spam category.
Regression Analysis
Supervised learning is also adept at regression tasks, where the algorithm predicts a continuous numerical output. An example is predicting house prices based on features such as square footage, number of bedrooms, and location. The model learns from a dataset with labeled examples, enabling it to generalize and estimate the price of a new house accurately.
Handwriting Recognition
In the realm of pattern recognition, supervised learning finds application in handwriting recognition systems. These systems are trained on labeled datasets containing examples of handwritten characters. The algorithm learns to recognize the unique features of each character and can subsequently transcribe handwritten text into machine-readable text with impressive accuracy.
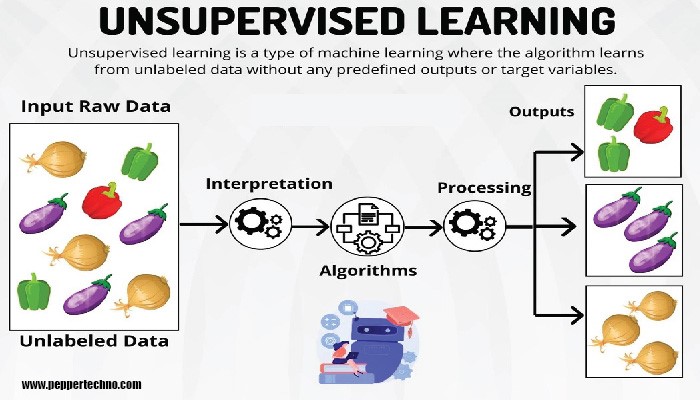
II. Unveiling Unsupervised Learning
Unsupervised learning, on the other hand, involves training the algorithm on an unlabeled dataset, without explicit instructions on the output. The objective is for the model to discover inherent patterns, relationships, or structures within the data.
Clustering
Clustering is a prime example of unsupervised learning, where the algorithm groups similar data points together based on inherent similarities. An application of clustering is customer segmentation in marketing. By analyzing customer behavior and purchase patterns, the algorithm can identify distinct segments within the customer base, allowing businesses to tailor their marketing strategies accordingly.
Dimensionality Reduction
Unsupervised learning is also instrumental in dimensionality reduction, a technique that involves simplifying the dataset while retaining essential information. Principal Component Analysis (PCA) is a popular method that falls under this category. By extracting the most significant features from the data, PCA aids in reducing computational complexity and improving model efficiency.
Anomaly Detection
Detecting anomalies or outliers in data is another application of unsupervised learning. In industries such as finance, anomaly detection algorithms scrutinize transactions to identify unusual patterns that might indicate fraudulent activity. These models learn to distinguish normal behavior from irregularities, contributing to enhanced security measures.
III. Bridging the Gap: Semi-Supervised Learning
Semi-supervised learning represents a hybrid approach that combines elements of both supervised and unsupervised learning. This method is particularly useful when acquiring labeled data is expensive or time-consuming.
Augmenting Labeled Data
In scenarios where obtaining a fully labeled dataset is challenging, semi-supervised learning can be employed to augment the existing labeled data with unlabeled examples. This approach enhances the model’s generalization capabilities and improves performance, especially in domains where obtaining labeled data is a bottleneck.
Active Learning
Active learning is another aspect of semi-supervised learning, where the algorithm is actively involved in selecting the most informative instances for labeling. This iterative process helps the model focus on crucial data points, accelerating the learning process and reducing the need for extensive labeled datasets.
Conclusion
In the vast landscape of machine learning, both supervised and unsupervised learning play indispensable roles, each contributing unique capabilities to the realm of artificial intelligence. Supervised learning excels in tasks that require precise predictions and classifications, while unsupervised learning unveils hidden patterns and structures within data. As technology continues to advance, the synergy between these two paradigms, as seen in semi-supervised learning, will undoubtedly lead to even more sophisticated and powerful machine learning applications. The examples presented in this article illustrate the practical applications of these learning approaches, showcasing their impact across various industries and domains.